스트림과 네트웍
글/윤경구
1999년 4월호 마소 주니어 원고입니다.
필자가 처음 자바 언어를 만났을 때 가장 답답했던 부분은 한글 지원 문제였습니다. 한반도에 거주하는 프로그래머라면 한글을 원활하게 사용할 수 없는 프로그래밍 언어를 고운 시선으로 바라볼 수 없을 것입니다.
자바는 초기 설계에서부터 국가나 국어에 관계없이 프로그램을 개발할 수 있도록 지원하기 위해 내부적으로 char 유형을 8비트가 아닌 부호 없는 16비트로 지정하였으며, 문자 코드를 국제 표준인 유니코드로 처리하게 하였습니다. 하지만 자바의 첫 공식 버전인 JDK 1.0은 한글 등을 지원하는 클래스에 심각한 버그가 있었습니다. 자바 언어를 만든 대머리 아저씨, 제임즈 고슬링 씨가 각국의 문자를 나타내는 표준인 유니코드를 잘못 이해하고 있었던 때문이지요.
이 문제는 다음 버전인 JDK 1.1부터 버그가 수정되고, 다양한 국가, 언어를 지원하면서부터 거의 완전히 해결되었습니다. 이제 자바는 다중 플랫폼 프로그램을 만들뿐만 아니라 하나의 코드로 다양한 국가와 국어를 지원하는 프로그램을 만들 수 있습니다. 진정한 의미에서 수많은 플랫폼에서 실행되는 프로그램을 만드는 언어가 된 것입니다.
자바는 동일한 프로그램이 국가, 국어, 운영 체제, 하드웨어 환경 등의 장벽을 넘어 실행될 수 있도록 할뿐만 아니라 인터넷 시대에 태어난 프로그래밍 언어답게 인터넷으로 연결되는 수많은 컴퓨터들을 하나로 묶어주는 역할도 하고 있습니다. 바로 네트웍에 대한 지원을 기본 기능으로 포함하고 있기 때문입니다. 네트웍 분산 환경을 구성하는 통신 규약인 TCP/IP를 지원하는 것은 물론, 이에 기반한 월드와이드웹 규약인 HTTP, 인터넷 파일 전송 규약인 FTP 등을 직접 지원하기도 합니다. 인터넷 및 유,무선 네트웍 규약으로 지구촌이 하나로 엮어져 가는 시대의 프로그래밍엔 자바가 이제 빠질 수 없는 핵심 개발 언어가 되었습니다.
이번 호에서는 네트웍 입출력은 물론, 표준 입출력, 파일 입출력 등 자바의 입출력에 사용되는 스트림 기능을 중심으로 한글을 사용하기 위한 문자셋 변환까지 알아보도록 합니다.
1. 입출력 스트림
윈도우의 도스 창이나 유닉스 셸로부터 입력을 받기 위해서 보통 표준 입력을 사용하고 또 도스 창이나 셸로 결과나 에러를 출력하기 위해서는 표준 출력과 표준 에러를 사용합니다. 또, 파일을 읽고 쓰기 위해서는 파일 입출력이 필요하고 네트웍을 통해 데이터를 주고 받기 위해서는 네트웍 입출력이 필요합니다.
자바는 이러한 입출력을 사용하는 데에 스트림이란 방식을 사용합니다. 스트림은 방향이 있는 하나의 흐름을 뜻하는 말로, 보통 8비트 바이트로 구성된 데이터들의 일련의 흐름을 나타냅니다.
스트림은 순차적인 흐름이기 때문에 내부적으로 먼저 들어온 것이 먼저 나가는 선입선출(FIFO) 구조로 구현됩니다. 자바의 모든 입력과 출력은 이러한 스트림 구조로 만들어집니다. 단 하나 예외가 있는데 바로 임의 접근 파일을 나타내는 RandomAccessFile 클래스입니다. 임의 접근 파일에서는 순차적으로 읽거나 쓰는 것이 아니라 파일의 시작점으로부터의 거리(오프셋)를 지정하여 임의의 위치에 바로 접근하여 읽거나 쓸 수 있습니다.
1.1 입출력 스트림 클래스
자바에서 스트림 구조를 나타내는 여러 가지 클래스들은 모두 java.io 패키지에 속하며 InputStream 클래스 혹은 OutputStream 클래스를 상속하여 만들어집니다. 입력에 관계된 여러 가지 스트림들은 InputStream 클래스의 자식 클래스들이고 출력에 관계된 여러 스트림 클래스들은 OutputStream 클래스의 자식 클래스들입니다.
다음 표는 각각 java.io 패키지에 있는 여러 입력 및 출력 스트림 클래스들을 보여줍니다.
|
클래스 |
설명 |
|
InputStream |
모든 바이트 스트림 입력 클래스의 부모 클래스 |
|
ByteArrayInputStream |
바이트 배열로부터 읽어들이는 입력 스트림 클래스 |
|
FileInputStream |
파일을 읽어들이는 입력 스트림 클래스 |
|
FilterInputStream |
다른 입력 스트림의 데이터를 가공하는 입력 스트림 클래스 |
|
BufferedInputStream |
데이터를 읽어들일 때 내부 버퍼를 사용하도록 하는 입력 스트림 클래스 |
|
DataInputStream |
입력 스트림으로부터 자바 유형을 읽어들이는 입력 스트림 |
|
PushbackInputStream |
스트림으로부터 일정한 크기의 데이터를 읽었다가 안 읽은 상태로 되돌릴 수 있는 입력 스트림 |
|
ObjectInputStream |
저장된 객체 데이터를 읽어들이는 입력 스트림 |
|
PipedInputStream |
생성된 파이프로부터 읽어들이는 입력 스트림 |
|
SequenceInputStream |
여러 입력 스트림을 차례로 하나의 연결된 입력 스트림으로 간주하게 해주는 입력 스트림 |
|
클래스 |
설명 |
|
OutputStream |
모든 바이트 스트림 출력 클래스의 부모 클래스이다. |
|
ByteArrayOutputStream |
바이트 배열로 쓰는 출력 스트림 클래스 |
|
FileOutputStream |
파일로 쓰는 출력 스트림 클래스 |
|
FilterOutputStream |
다른 출력 스트림의 데이터를 가공하는 출력 스트림 클래스 |
|
BufferedOutputStream |
데이터를 쓸 때 내부 버퍼를 사용하도록 하는 출력 스트림 클래스 |
|
DataOutputStream |
출력 스트림으로 자바 유형을 내보내는 출력 스트림 |
|
PrintStream |
다양한 데이터 유형을 간단하게 출력하는 편의적인 출력 스트림 |
|
ObjectOutputStream |
객체 데이터를 내보내는 출력 스트림 |
|
PipedOutputStream |
파이프를 생성하여 데이터를 내보내는 출력 스트림 |
1.2 입출력 스트림을 사용한 파일 복사
입출력 스트림을 사용하는 방법을 배우려면 전형적인 사용 예를 보는 것이 가장 좋을 것입니다. 파일 입출력 스트림 클래스들을 사용하여 이진 파일을 복사하는 자바 프로그램을 만들어보면서 사용법을 익히도록 하겠습니다.
파일 입출력에 해당하는 스트림 클래스는 각각 FileInputStream과 FileOutputStream입니다.
먼저 FileInputStream 혹은 FileOutputStream을 생성하는 방법은 다음과 같습니다.
// 원천 파일인 source.dat 파일로부터 읽어들이는 파일 입력 스트림을 만들 경우
FileInputStream fileIn = new FileInputStream("source.dat");
// 목적 파일인 destine.dat 파일로 쓰는 파일 출력 스트림을 만들 경우
FileOutputStream fileOut = new FileOutputStream("destine.dat");
또, 파일을 읽고 쓸 때 효율을 높이기 위하여 파일 입출력 스트림을 내부적으로 버퍼를 사용하는 버퍼 입출력 스트림으로 변환하여 사용할 것입니다. Buffered<Input/Output>Stream, Data<Input/Output>Stream, PrintStream 등은 클래스 상속 계층 구조에서 확인할 수 있듯이 Filter<Input/Output>Stream 클래스의 자식 클래스인데 다른 입출력 스트림의 데이터를 가공하여 프로그래머가 편리하게 사용할 수 있도록 도와주는 기능을 하는 입출력 클래스들입니다.
위의 fileIn, fileOut 입출력 스트림 객체를 사용하여 각각 버퍼 입출력 스트림을 생성하는 방법은 다음과 같습니다.
// 다음에서 512는 버퍼 입출력 클래스가 내부적으로 사용할 버퍼의 크기를 지정하는 값입니다.
// 버퍼 크기를 인자로 받지 않는 버전의 생성자는 기본값으로 512를 사용합니다.
BufferedInputStream in = new BufferedInputStream(fileIn, 512);
BufferedOutputStream out = new BufferedOutputStream(fileOut, 512);
파일 복사 프로그램은 원천 파일의 버퍼 입력 스트림으로부터 데이터를 읽어들여 목적 파일의 버퍼 출력 스트림으로 데이터를 쓰는 일을 할 것입니다. 데이터를 읽어들일 때에는 read() 메소드를, 쓸 때에는 write() 메소드를 사용합니다.
입력 스트림으로부터 read() 메소드의 반환값이 -1이면 스트림의 끝에 도달한 것을 뜻합니다. 이 경우에는 파일을 모두 읽었음을 뜻합니다. 그러므로 여기에서는 while 반복문을 사용하여 read() 메소드의 반환값이 0과 같거나 크면 읽은 데이터를 출력 스트림으로 쓰기를 반복하면 됩니다.
byte buffer[] = new byte[1024]; // 읽은 바이트 데이터들을 저장할 버퍼
try {
int nRead=0; // read() 메소드가 한 번에 읽은 바이트 수를 저장할 변수
while ((nRead=in.read(buffer, 0, 1024))>=0) {
out.write(buffer, 0, nRead); // 읽어들인 바이트 데이터를 씁니다.
}
} catch (IOException ie) { // 읽고 쓰는 도중 예외 발생하면 처리합니다.
System.err.println("\n에러 : "+ie.getMessage());
}
finally { // 입출력 스트림 사용이 끝났으면 반드시 리소스를 해지하도록 합니다.
try { in.close(); } catch (IOException ie) { }
try { out.close(); } catch (IOException ie) { }
}
입출력 스트림을 사용할 때 주의할 점 중 하나는 반드시 입출력 스트림 사용이 끝나면 할당된 리소스를 해지해줘야 한다는 것입니다. 각 스트림은 프로세스 단위로 할당되는 리소스를 사용하고 있으므로 반드시 close()를 해줘야 메모리 유출 등을 막을 수가 있습니다. 위에서 보듯이 예외가 발생하는 상황에서도 close()를 수행할 수 있도록 해야 합니다. try { ... } finally { } 블록은 예외 발생 시에도 close() 실행을 보장해주는 방법으로 사용할 수 있습니다.
완성된 소스 코드는 다음과 같습니다.
import java.io.*;
class FileCopy {
public static void main(String args[]) {
if (args.length < 2) {
System.out.println("사용법 : java FileCopy 원천파일 목적파일");
System.exit(1);
}
if (args[0].equals(args[1])) {
System.out.println("에러 : 원천파일과 목적파일이 같습니다.");
System.exit(1);
}
BufferedInputStream in = null; // 널 값으로 초기화
try {
in = new BufferedInputStream(
new FileInputStream(args[0]), // args[0]는 원천 파일 이름
1024); // 버퍼 크기
}
catch (FileNotFoundException fnfe) {
System.err.println("에러 : "+args[0]+" 파일을 찾을 수 없습니다.");
System.exit(1);
}
catch (Exception e) {
System.err.println("에러 : "+e.toString());
System.exit(1);
}
BufferedOutputStream out = null; // 널 값으로 초기화
try {
out = new BufferedOutputStream(
new FileOutputStream(args[1]), // args[1]은 목적 파일 이름
1024); // 버퍼 크기
}
catch (IOException ie) {
System.err.println("에러 : "+args[1]+" 파일을 만들 수 없습니다.");
System.exit(1);
}
catch (Exception e) {
System.err.println("에러 : "+e.getMessage());
System.exit(1);
}
// 복사하기
byte buffer[] = new byte[1024]; // 버퍼 할당
int nWrote=0;
System.out.println(args[0]+" 파일을 "+args[1]+" 파일로 복사하고 있습니다.");
try {
int nRead=0;
while ((nRead=in.read(buffer, 0, 1024))>=0) {
out.write(buffer, 0, nRead);
nWrote+=nRead;
System.out.print("*"); // 복사 중임을 표시
}
System.out.println();
System.out.println(args[1]+" 파일에 "+nWrote+" 바이트를 썼습니다.");
} catch (IOException ie) {
System.err.println("\n에러 : "+ie.getMessage());
}
finally {
try { in.close(); } catch (IOException ie) { }
try { out.close(); } catch (IOException ie) { }
}
}
}
<예제> 입출력 스트림을 사용한 파일 복사 프로그램
다음은 실행한 예입니다.
E:\HNC\WORK\maso4>java FileCopy c:\windows\telnet.exe telnet.exe
c:\windows\telnet.exe 파일을 telnet.exe 파일로 복사하고 있습니다.
******************************************************************
telnet.exe 파일에 66672 바이트를 썼습니다.
1.3 바이트 스트림과 문자 스트림
InputStream 클래스와 OutputStream 클래스를 상속하는 입출력 스트림은 바이트 단위의 스트림을 사용합니다. 하지만 자바에서는 문자를 16비트 단위의 유니코드로 표현합니다. 따라서 바이트 단위를 통해 입출력된 스트림으로 자바의 문자열을 표현하려면 문자 인코딩에 따라 문자열을 바이트 배열로 변환하여 전송한 다음, 전송된 바이트 배열을 원래의 문자열로 다시 변환하는 과정을 거쳐야 합니다. 자바는 이러한 불편을 해결하고 보다 효율적으로 문자열을 스트림을 통하여 읽고 쓸 수 있도록 유니코드 문자를 사용하는 문자 입출력 스트림 클래스를 제공합니다.
바이트 입출력 스트림이 InputStream 클래스와 OutputStream 클래스의 자식 클래스들이듯이, 문자 입출력 스트림 클래스는 입력을 담당하는 Reader 클래스와 출력을 담당하는 Writer 클래스를 상속하는 자식 클래스들이며, 각 바이트 입출력 스트림 클래스에는 대응되는 문자 입출력 스트림 클래스들이 제공됩니다.
다음은 바이트 스트림과 문자 스트림 클래스들을 대응시킨 표입니다.
|
바이트 입력 스트림 클래스 |
문자 입력 스트림 클래스 |
|
InputStream |
Reader |
|
ByteArrayInputStream |
CharArrayReader |
|
FileInputStream |
FileReader |
|
FilterInputStream |
FilterReader |
|
BufferedInputStream |
BufferedReader |
|
DataInputStream |
× |
|
PushbackInputStream |
PushbackReader |
|
ObjectInputStream |
× |
|
PipedInputStream |
PipedReader |
|
SequenceInputStream |
× |
|
× |
LineNumberReader (문자열을 한 줄씩 읽어들이는 클래스) |
|
× |
InputStreamReader (바이트 입력 스트림을 문자 입력 스트림으로 변환하는 클래스) |
|
바이트 출력 스트림 클래스 |
문자 출력 스트림 클래스 |
|
OutputStream |
Writer |
|
ByteArrayOutputStream |
CharArrayWriter |
|
FileOutputStream |
FileWriter |
|
FilterOutputStream |
FilterWriter |
|
BufferedOutputStream |
BufferedWriter |
|
DataOutputStream |
× |
|
PrintStream |
PrintWriter |
|
ObjectOutputStream |
× |
|
PipedOutputStream |
PipedWriter |
|
× |
StringWriter (String으로 출력하는 출력 스트림 클래스) |
|
× |
OutputStreamWriter (문자 출력 스트림의 문자 데이터들을 인코딩에 맞게 바이트 데이터로 변환하여 바이트 출력 스트림으로 내보내는 클래스) |
InputStreamReader 클래스와 OutputStreamWriter 클래스는 바이트 입출력 스트림과 문자 입출력 스트림을 상호 변환하는 특별한 클래스입니다. InputStreamReader 클래스는 바이트 입력 스트림으로부터 바이트 데이터를 읽어들여 지정한 인코딩에 따라 문자들로 변환하는 문자 입력 스트림이며, 마찬가지로 OutputStreamWriter 클래스는 문자들을 지정한 인코딩에 따라 바이트로 변환하여 지정된 바이트 출력 스트림으로 내보내는 역할을 하는 클래스입니다.
|
문자 인코딩 자바는 문자를 내부적으로 유니코드로 처리하며, 자바의 문자 하나가 차지하는 크기는 16비트입니다. 하지만 일상적으로 우리가 접하는 텍스트 파일들은 유니코드에 따라 만들어지지 않았습니다. 대부분의 운영 체제가 아직 유니코드를 제대로 지원하지 않기 때문에 운영 체제와 소프트웨어에 따라 여러 가지 다른 인코딩으로 한글을 표현합니다. 자바에서 지원하는 한글 인코딩은 Cp933, MS949(혹은 Cp949), EUC_KR, ISO2022KR 등입니다. 이 중 가장 일반적으로 사용되는 것은 대부분의 한글화된 운영 체제에서 자바의 기본 인코딩으로 처리할 EUC_KR 인코딩입니다. EUC_KR 인코딩은 KSC5601로 표현되기도 합니다. 대부분의 한글 텍스트는 EUC_KR 인코딩에 따라 만들어지며 흔히 완성형 한글 코드라고 부른다. 윈도우 95/98, 윈도우 NT 등의 마이크로소프트 윈도우 시스템은 완성형 한글 코드에 좀더 많은 한글을 표현할 수 있도록 한글 코드를 추가한 통합 완성형을 지원하는데 이 코드 인코딩을 MS949 혹은 Cp949라고 합니다. MS949 인코딩은 마이크로소프트 한글 윈도우 95 이후 버전에서만 제대로 읽을 수 있으므로 주의해야 합니다. 한글 윈도우 NT 4.0 이후 버전부터는 내부적으로 유니코드 2.0을 지원한다고 합니다. 문자 인코딩이 중요한 이유는 유니코드가 아닌 다른 인코딩으로 된 텍스트 문서를 읽어들여 제대로 표현하려면 자바에서는 유니코드로 변환을 해야 하고, 또 화면에 보여줄 때에는 각 운영 체제의 글꼴을 사용하여 보여줘야 하므로 (각 운영체제의 글꼴들은 운영 체제의 인코딩에 맞게 설계됩니다) 시스템에 고유한 인코딩으로 변환할 필요가 있기 때문입니다. 다음 예제는 현재 시스템에서 사용되는 자바의 기본 인코딩을 보여주는 간단한 예제입니다.
<예제 4> 기본 인코딩을 보여주는 예제
JDK 1.2의 경우 한글 윈도우 95/98에서 이 프로그램을 실행하면 MS949가 기본 인코딩으로 출력됩니다. |
1.4 문자 입출력 스트림을 사용한 텍스트 파일 복사
텍스트 파일을 복사할 때에도 물론 앞의 바이트 스트림 복사를 사용해도 아무런 문제가 없을 것입니다. 하지만, 텍스트 파일의 내용을 화면에 보여주고자 할 경우에는 바이트 입출력 스트림으로는 곤란합니다. 전형적인 문자 입출력 스트림 사용법을 텍스트 복사 프로그램을 통해 알아보도록 합시다.
먼저 원천 파일로부터 BufferedReader 객체를 만드는 것은 BufferedInputStream 객체를 만드는 것과 거의 같습니다. 다만 InputStream을 Reader로 바꾸었다는 점만 다릅니다.
// "source.txt" 파일로부터 1024 바이트 크기의 버퍼 입력 문자 스트림 객체 생성
in = new BufferedReader(new FileReader("source.txt"), 1024);
목적 파일에 쓸 출력 스트림으로 BufferedWriter 객체를 만드는 것도 BufferedOutputStream 객체를 만드는 방법과 거의 같지만, 여기에서는 좀더 편리하게 사용할 수 있는 PrintWriter 객체를 만들어봅니다.
// 자동 플러시 방식으로 "destine.txt" 파일로 쓰는 PrintWriter 객체 생성
out = new PrintWriter(new FileWriter("destine.txt"), true);
PrintWriter 클래스 생성자의 두 번째 인자는 println() 메소드를 사용할 경우 자동으로 버퍼를 플러시할 것인지를 결정합니다. 실제 텍스트 파일을 복사할 때에는 원천 텍스트 파일의 내용을 한 줄씩 읽어들여 목적 파일로 쓰는 방식을 사용합니다.
try {
String line=null;
while ((line=in.readLine())!=null) {
out.println(line);
// println() 메소드는 IOException을 던지지 않으므로 사용한 다음에는
// 수행 도중에 에러가 발생하지 않았는지 반드시 checkError() 메소드를
// 사용하는 것이 좋습니다.
if (out.checkError())
throw new IOException("파일 쓰기 에러입니다.");
}
} catch (IOException ie) {
System.err.println("\n에러 : "+ie.getMessage());
}
finally {
try { in.close(); } catch (IOException ie) { }
// PrintWriter는 close()에도 예외를 던지지 않는다.
out.close();
}
전체 소스 코드는 다음과 같습니다.
import java.io.*;
class TextCopy {
public static void main(String args[]) {
if (args.length < 2) {
System.out.println("사용법 : java TextCopy 원천파일 목적파일");
System.exit(1);
}
if (args[0].equals(args[1])) {
System.out.println("에러 : 원천파일과 목적파일이 같습니다.");
System.exit(1);
}
BufferedReader in = null; // 널 값으로 초기화
try {
in = new BufferedReader(
new FileReader(args[0]), // args[0]가 원천 텍스트 파일 이름
1024); // 버퍼 크기
}
catch (FileNotFoundException fnfe) {
System.err.println("에러 : "+args[0]+" 파일을 찾을 수 없습니다.");
System.exit(1);
}
catch (Exception e) {
System.err.println("에러 : "+e.getMessage());
System.exit(1);
}
PrintWriter out = null; // 널 값으로 초기화
try {
out = new PrintWriter(
new FileWriter(args[1]), // args[1]은 목적 텍스트 파일 이름
true); // 자동 플러시 모드
}
catch (IOException ie) {
System.err.println("에러 : "+args[1]+" 파일을 만들 수 없습니다.");
System.exit(1);
}
catch (Exception e) {
System.err.println("에러 : "+e.toString());
System.exit(1);
}
// 복사하기
int nWrote=0;
System.out.println(args[0]+" 파일을 "+args[1]+" 파일로 복사하고 있습니다.");
try {
String line=null;
while ((line=in.readLine())!=null) {
out.println(line);
// println() 메소드는 IOException을 던지지 않으므로 사용한 다음에는
// 수행 도중에 에러가 발생하지 않았는지 반드시 checkError()
// 메소드를 사용하는 것이 좋습니다.
if (out.checkError())
throw new IOException("파일 쓰기 에러입니다.");
nWrote+=line.length()+1;
System.out.println(line); // 표준 출력으로 파일 내용 출력
}
System.out.println();
System.out.println(args[1]+" 파일에 "+nWrote+" 문자를 썼습니다.");
} catch (IOException ie) {
System.err.println("\n에러 : "+ie.getMessage());
}
finally {
try { in.close(); } catch (IOException ie) { }
// PrintWriter는 close()에서도 예외를 던지지 않는다.
out.close();
}
}
}
<예제> 텍스트 파일 복사 프로그램
|
표준 입출력 스트림 사용하기 자바에서는 표준 입출력 스트림을 System 클래스의 in, out, err 세 개의 정적 상수 필드를 사용하여 제어하도록 합니다. System.in은 표준 입력에 해당하는 InputStream 객체이며, System.out과 System.err는 표준 출력과 표준 에러를 각각 나타내는 PrintStream 객체입니다. HelloWorld 프로그램을 만들 때부터 사용해오던 System.out.println("Hello, world."); 는 표준 출력 스트림을 나타내는 System.out 객체의 println() 메소드를 호출하는 것입니다. 다음은 간단하게 표준 입력(키보드)으로부터 입력을 받아 표준 출력(모니터)으로 다시 출력하는 에코 프로그램입니다.
<예제> 표준 입력을 표준 출력으로 에코하는 프로그램
엄밀하게 따지면 System.out으로 출력되는 String 객체는 해당 운영 체제의 기본 인코딩에 따라 바이트로 변환되어 출력됩니다. 기본 인코딩이 한글을 표시하는 EUC_KR 혹은 MS949로 설정되어 있다면 윈도우 98/NT 등을 포함한 운영 체제가 이 바이트들의 연속을 한글로 인식하여 결과적으로는 2바이트 문자로 처리되는 한글을 제대로 디스플레이할 것입니다. 하지만, 좀더 정확하게 하자면 문자열, 즉 String 객체를 출력하고자 할 때에는 표준적인 방법인 PrintWriter 클래스를 사용하는 것이 좋습니다. PrintWriter out = new PrintWriter(System.out, true); 위와 같이 표준 출력을 인쇄 문자 스트림으로 변환하여 표준 출력으로 나가는 스트림을 문자 스트림으로 처리할 수 있습니다. |
2. 네트웍 프로그래밍
자바는 네트웍 프로그래밍 언어입니다. 적어도 글로벌 네트웍 시대의 프로그래밍 언어임에는 분명합니다.
인터넷을 배경으로 태어났고 인터넷과 분산 환경을 위한 독특한 프로그램 실행 형태인 애플릿을 지원하는 것을 봐도 확인할 수 있습니다. 애플릿이라는 프로그램은 웹 브라우저라는 실행 환경이 인터넷을 통해서 프로그램 실행 코드가 다운로드하여 실행하므로 그 자체가 네트웍 프로그램이며 네트웍을 사용하여 애플릿이 필요한 리소스를 구하기도 하였습니다. 물론 프로그래머는 이것이 네트웍 기능을 사용하고 있다는 별다른 자각 없이, 자신도 모르게 애플릿이라는 복잡한 네트웍 프로그램을 만들어왔습니다. 이것은 자바가 네트웍에 대한 여러 가지 기능을 기본적으로 지원하고 있으며, 애플릿은 이러한 네트웍 지원 기능 위에 구현되어 있는 프로그램이기 때문입니다. 자바 프로그래머가 이 애플릿(Applet 클래스)을 단순히 클래스 상속하여 몇 가지 메소드만 구현해주면 훌륭하게 인터넷을 가로질러 실행되는 프로그램이 되곤 합니다.
여기에서는 이 애플릿들이 배경으로 삼고 있는 기반 네트웍 기능인 자바의 TCP/IP 지원 기능(소켓)과 TCP/IP에 기반한 전송 프로토콜인 HTTP, FTP 등을 알아봅니다.
2.1 URL 프로그래밍
URL은 Uniform Resource Locator의 머리글자로 인터넷 상의 어떤 리소스의 위치를 나타내는 일종의 주소 표기입니다. URL은 기본적으로 인터넷 프로토콜과 서비스를 제공하는 서버 주소, 그리고 서버 안에서의 리소스 위치 등으로 구성되는데, 자바는 이러한 URL 문자열을 다루는 URL 클래스를 java.net 패키지에서 제공하고 있습니다.
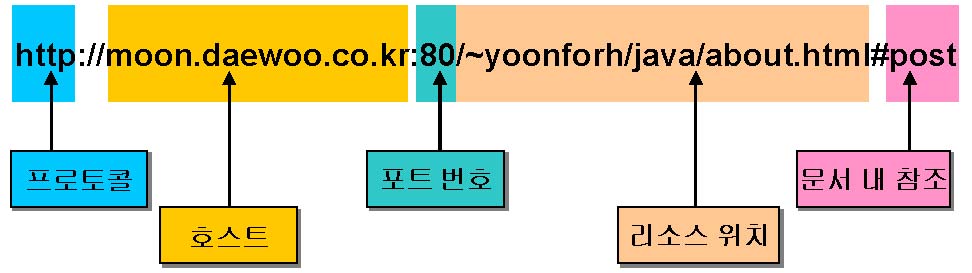
<그림> URL의 각 구성 요소들
위 그림은 URL 문자열의 각 구성 요소들을 보여주는 예로, URL 클래스를 사용하여 다음과 같이 각 구성요소를 가져올 수 있습니다.
// 지정된 문자열의 URL을 가지는 URL 객체를 생성
URL url = new
URL("http://moon.daewoo.co.kr:80/~yoonforh/java/about.html#post");
// 프로토콜 이름 출력. http가 출력됩니다.
System.out.println("프로토콜 :"+url.getProtocol( ));
// 호스트 이름 출력. moon.daewoo.co.kr이 출력됩니다.
System.out.println("호스트 :"+url.getHost( ));
// 포트 번호 출력. 위에서처럼 ':80'을 넣어 명시적으로 포트를 지정한 경우에만
// 제대로 값을 리턴합니다. 포트 번호를 지정하지 않으면 -1을 리턴합니다.
// -1인 경우에는 각 프로토콜이 사용하는 기본 포트로 간주하게 됩니다.
// http 프로토콜의 경우에는 80, ftp 프로토콜은 23이 기본 포트 번호입니다.
System.out.println("포트 번호 :"+url.getPort( ));
// 리소스 위치 출력. /~yoonforh/java/about.html이 출력됩니다.
System.out.println("파일 이름 :"+url.getFile( ));
// 문서 내에서의 참조 위치 출력. post가 출력됩니다.
System.out.println("참조 :"+url.getRef());
자바는 인터넷 프로토콜 중 http 프로토콜(하이퍼텍스트 전송 프로토콜, 월드와이드웹에서 사용하는 프로토콜)과 ftp 프로토콜(파일 전송 프로토콜)을 기본 지원합니다. 따라서 http 프로토콜이나 ftp 프로토콜을 사용하여 입출력 스트림을 열고 닫는 것은 아주 쉽습니다. URL 객체로부터 입출력 스트림을 만들 때에는 URLConnection 클래스를 사용할 수 있습니다.
URLConnection 클래스는 지정된 URL로 직접 연결을 설정하여 입출력 스트림을 만들 수 있는 메소드들을 제공합니다. URL 객체로부터 URL 연결을 관리하는 URLConnection 객체를 구하려면 openConnection( ) 메소드를 사용하면 됩니다.
try {
// URL 객체로부터 URL 연결 관리 객체 인스턴스 생성
URLConnection connection = url.openConnection();
// URL 연결 관리 객체로부터 입력 스트림 생성
InputStream in = connection.getInputStream();
// URL 연결 관리 객체로부터 출력 스트림 생성
OutputStream out = connectioin.getOutputStream();
} catch (IOException ie) {
// 예외 처리
}
다음 예제는 URL 클래스를 사용하여 http 프로토콜 혹은 ftp 프로토콜을 통해 접근할 수 있는 파일 리소스를 다운로드하는 프로그램입니다. URL 클래스를 사용하여 입출력 바이트 스트림을 열었다는 점을 제외하면 앞에서 다룬 파일 복사 프로그램과 크게 다를 것이 없습니다. 하지만, 이 프로그램은 가끔 유용하게 사용할 수가 있습니다. 여러 개의 파일을 배치 작업으로 http 혹은 ftp 프로토콜을 사용하여 다운로드하고자 할 때 이 프로그램을 사용하면 간단하게 배치 작업을 수행할 수 있을 것입니다.
import java.net.*;
import java.io.*;
class URLDownload {
public static void main(String args[]) {
if (args.length<1) {
System.out.println("Usage : java URLDownload URL");
System.out.println("Ex : java URLDownload "
+"http://moon.daewoo.co.kr/~yoonforh/new.gif");
System.exit(1);
}
// 버퍼 입출력 스트림의 초기값을 널로 한다.
BufferedInputStream in = null;
BufferedOutputStream out = null;
try {
URL url = new URL(args[0]); // URL 객체 생성
// URL의 리소스 주소에서 파일 이름만 추출한다.
String filename=url.getFile().substring(url.getFile().lastIndexOf('/')+1);
// 지정된 URL로부터 입력 스트림을 연다.
in = new BufferedInputStream(url.openStream(), 1024);
out = new BufferedOutputStream(
new FileOutputStream(filename));
byte[] buffer=new byte[1024];
int nRead=0, nWrote=0;
System.out.println(filename+" 파일을 다운로드하고 있습니다.");
// 입력이 -1일(have no data to read) 때까지 계속해서 읽어서 파일로 쓴다.
while ((nRead = in.read(buffer, 0, 1024)) >= 0) {
out.write(buffer, 0, nRead);
nWrote+=nRead;
System.out.print("#"); // 파일 다운로드 중임을 표시
}
System.out.println();
System.out.println(filename+" 파일에 "+nWrote+" 바이트를 썼습니다.");
} catch (MalformedURLException mue) {
System.out.println("MalformedURLException: " + mue.getMessage());
} catch (IOException ie) {
System.out.println("IOException: " + ie.getMessage());
}
finally {
try { in.close(); } catch (IOException ie) { }
try { out.close(); } catch (IOException ie) { }
}
}
}
<예제> URL에 지정된 http나 ftp 프로토콜을 사용하여 파일을 다운로드하는 프로그램
2.2 네트웍 소켓
소켓은 원래 전구나 전기 플러그를 꽂는 기구를 뜻하는 단어입니다. 그렇다면 네트웍 프로그래밍에서 사용되는 소켓은 어떤 의미를 가질까요? 네트웍에도 무엇인가 플러그와 소켓 같이 연결할 수 있는 방법이 있다는 뜻일까요?
네트웍을 통하여 두 개의 프로그램이 서로 연결되려면 다음 요소들이 갖추어져야 합니다.
① 통신 프로토콜 : 연결될 두 프로그램이 서로 통신할 때 사용할 규약.
통신 프로토콜에는 먼저 연결을 구성한 다음 데이터를 주고받는 연결형 프로토콜(TCP 프로토콜)과 연결을 구성하지 않고 데이터를 주고받는 비연결형 프로토콜(UDP 프로토콜)이 있습니다. 자바에서는 java.net 패키지의 Socket, ServerSocket 클래스를 사용하여 연결형 통신을 지원하고, DatagramSocket 클래스를 사용하여 비연결형 통신을 지원합니다.
②,③ 지역과 원격지의 호스트 주소 : 한쪽 호스트의 네트웍 주소.
호스트 주소는 앞의 URL에서 보았듯이 마침표(.)로 구분되는 여러 단계의 문자열로 표현할 수 있습니다. 실제 네트웍 주소는 이 문자열을 네 단계의 정수값으로 변환하여 지정합니다. 예를 들어 moon.daewoo.co.kr이란 호스트 이름은 실제로는 165.133.1.5라는 네 단계의 정수값을 가진 네트웍 주소로 변환됩니다.
④,⑤ 지역과 원격지의 프로세스 : 호스트 안에서 실행되는 프로세스를 지정.
보통 포트 번호를 사용하여 프로세스를 지정하게 됩니다. URL에서 잠시 설명했지만 http 프로토콜은 80, ftp 프로토콜은 23과 같이 각 프로세스(서비스)가 사용할 포트 번호가 지정됩니다. 사용자가 포트 번호를 자신의 프로그램에 부여할 때에는 1024 이상의 값을 줘야 하고 자신의 호스트에서 실행되는 다른 프로세스와 포트번호가 중복되지 않도록 주의해야 합니다.
연결을 구성하는 다섯 가지 요소 중 한쪽 호스트에서 지정해야 하는 부분인 ① 통신 프로토콜, ② 지역 호스트 주소, ③ 지역 프로세스 세 가지 요소를 흔히 전송 주소 혹은 소켓이라고 부릅니다. 즉, 소켓은 네트웍에서 연결을 구성하기 위한 한쪽 끝을 뜻하는 개념으로 사용되는 것입니다. 네트웍 프로그래밍의 소켓에는 구성된 한쪽 끝과 다른쪽 끝을 서로 공유하는 통신 프로토콜을 사용하여 연결하기만 하면 네트웍 연결이 구성된다는 의미가 숨어 있는 것입니다.
2.3 서버/클라이언트 통신 모델
소켓을 사용한 프로그램은 보통 서버/클라이언트 모델이라고 하는 네트웍 통신 모델을 사용하게 됩니다. 서버는 네트웍 연결 요청을 기다리는 프로세스이며 클라이언트는 네트웍 연결을 요청하는 프로세스를 뜻합니다.
서버 프로세스는 특정한 포트 번호를 사용하여 자신의 호스트에서 연결의 반을 의미하는 소켓을 열어두고 누군가가 이 포트 번호로 접속해올 때까지 기다립니다.
클라이언트 프로세스는 서버 프로세스가 있는 호스트의 주소와 서버 프로세스가 사용하는 특정 포트 번호를 사용하여 서버 프로세스에게 연결을 요청합니다.
자바에서 서버 프로세스의 기본 역할은 ServerSocket 클래스를 사용하여 구현할 수 있으며 클라이언트 프로세스의 기본 역할은 Socket 클래스를 사용하여 구현할 수 있습니다.
다음 그림은 자바에서 연결형(TCP) 프로토콜을 사용하여 서버/클라이언트 모델을 구성할 때의 기본 통신 방법을 보여줍니다.
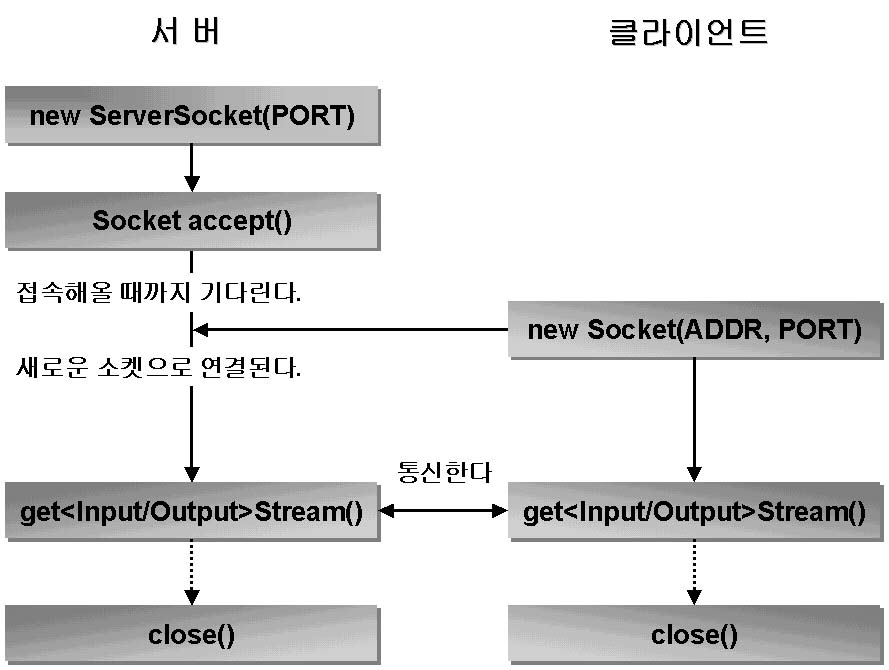
<그림> 자바의 연결형 서버/클라이언트 통신 모델
2.3.1 서버 프로그램의 골격 구현
위 그림의 서버/클라이언트 모델에 따라 서버 프로그램의 골격을 잡아보도록 합니다.
먼저 특정한 포트를 사용하는 서버 소켓 객체를 생성하여 클라이언트가 해당 포트로 접속해오기를 기다려야 합니다.
// 먼저 지정된 포트로 서버 소켓을 생성
ServerSocket server = null;
int port = 7001; // 특정한 포트 번호
try {
server = new ServerSocket(port);
} catch (IOException ie) {
System.err.println("Cannot create server socket:"+ie.toString( ));
}
일반적인 경우 하나의 서버 소켓은 여러 개의 클라이언트 접속을 동시에 처리할 수 있도록 구현됩니다.
일단 서버 소켓을 생성하면 accept( ) 메소드를 사용하여 클라이언트가 접속해올 때까지 기다리다가, 일단 접속이 되면 accept( ) 메소드의 리턴 값인 새로운 소켓 객체를 사용하여 접속된 클라이언트와 통신을 하면 됩니다.
// 무한 반복문을 돌면서 클라이언트가 접속해오면 각 클라이언트별로
// 연결을 생성하여 지정한 일을 한 후 연결을 닫습니다.
while (true) {
Socket socket = null;
try {
// 클라이언트가 접속해올 때까지 무한히 기다립니다.
// 클라이언트와 연결되면 새로운 소켓 객체가 리턴됩니다.
socket = server.accept();
// doSomething( ) 메소드는 실제 통신을 하는 메소드입니다.
doSomething(socket);
} catch (IOException ie) {
System.err.println("IOException:"+ie.getMessage( ));
} finally {
try { socket.close(); } catch (IOException ie) { }
}
}
보통 doSomething( ) 메소드는 클라이언트와 실제로 통신을 하는 부분으로 자바에서는 소켓 객체로부터 입력 및 출력 스트림 객체를 구하여 통신하게 될 것입니다.
InputStream in = socket.getInputStream( );
OutputStream out = socket.getOutputStream( );
2.3.2 클라이언트 프로그램의 골격 구현
클라이언트 프로그램의 경우에는 서버의 경우보다 좀더 간단한 골격을 가질 것입니다.
먼저 Socket 클래스 생성자를 사용하여 서버가 있는 원격 호스트의 특정 포트에 접속을 시도합니다. 별다른 예외가 발생하지 않고 생성자가 리턴되면 연결이 이루어진 것이므로 생성된 소켓 객체를 사용하여 서버와 통신하면 됩니다.
// 먼저 지정된 호스트 주소와 포트로 소켓을 생성합니다.
Socket socket = null;
String host = "moon.daewoo.co.kr"; // 서버가 있는 원격 호스트 지정
int port = 7001; // 서버가 사용하는 특정 포트 번호 지정
try {
socket = new Socket(host, port);
// doSeveralThings() 메소드는 서버와 약속했던 일을 할 것입니다.
doSeveralThings(socket);
} catch (UnknownHostException uhe) { // 호스트 주소를 이해할 수 없을 때
System.err.println("Unknown host:"+uhe.getMessage());
} catch (IOException ie) {
System.err.println("IOException:"+ie.getMessage());
} finally {
try { socket.close(); } catch (IOException ie) { }
}
2.4 브로드캐스트 서버/클라이언트 프로그램 구현
서버/클라이언트 모델을 구현하는 예제 프로그램을 실제로 작성해봅시다. 브로드캐스트 서버는 여러 개의 클라이언트와 동시에 연결되면서 각 클라이언트 간의 통신을 중개하는 기능을 가집니다. 서버는 어느 한 클라이언트가 메시지를 보내면 이 메시지를 현재 접속된 모든 클라이언트에게 보내는 일을 합니다.
클라이언트는 사용자가 텍스트필드에 입력한 내용을 서버로 보내며 또, 서버로부터 받은 메시지를 텍스트에리어에 디스플레이하는 애플릿으로 구현해보도록 합니다.
2.4.1 브로드캐스트 서버 프로그램
브로드캐스트 서버는 여러 명의 클라이언트가 동시에 접속할 수 있으며 현재 접속이 유지되고 있는 클라이언트 목록을 내부적으로 가지고 있다가 어느 클라이언트로부터 메시지가 도착하면 클라이언트 목록에 있는 모든 클라이언트에게 해당 메시지를 보내야 합니다. 이 때 클라이언트들의 목록을 관리하기 위해 java.util 패키지의 Vector 클래스를 사용할 수 있습니다. Vector 클래스는 크기가 변할 수 있는 객체 배열을 위해 주로 사용되는데 배열이 객체와 기본 자료형 모두에 사용될 수 있는 데 비해 Vector 클래스는 객체에만 사용될 수 있고 그 크기가 자동으로 변한다는 점에서 배열과 다릅니다.
Vector 클래스 등에 등록된 객체들을 차례로 순회하는 데 유용한 인터페이스로 Enumeration이 있는데 Enumeration 인터페이스를 사용하여 Vector 클래스에 등록된 String 객체들을 차례로 출력하려면 다음과 같은 방법을 사용합니다.
Vector vector=new Vector(); // 벡터 생성
... // 벡터의 원소들을 추가하는 부분
for (Enumeration e = vector.elements(); e.hasMoreElements() ; ) {
System.out.println((String) e.nextElement());
}
브로드캐스트 서버는 일반적인 소켓 서버의 골격을 그대로 가지며, 접속한 클라이언트별로 쓰레드를 생성하여 클라이언트가 어떤 메시지를 보낼 때까지 기다렸다가, 메시지가 도착하면 그 메시지를 모든 클라이언트에게 브로드캐스트하게 됩니다.
import java.io.*;
import java.net.*;
import java.util.*;
class BroadcastServer
{
final static int PORT = 8001;
ServerSocket server = null;
Vector clients = new Vector();
// 내부 클래스로 선언된 Client 클래스. 각 클라이언트과 접속이 이루어진 소켓을 관리하며
// 클라이언트마다 별도의 쓰레드로 이루어집니다.
class Client extends Thread {
Socket socket = null;
BufferedReader in = null;
PrintWriter out = null;
// 생성자
Client (Socket socket) throws IOException {
this.socket = socket;
this.in = new BufferedReader(
new InputStreamReader(socket.getInputStream()));
this.out = new PrintWriter(
new OutputStreamWriter(socket.getOutputStream()),
true /* 자동 플러시 모드 */);
start(); // 접속이 이루어진 클라이언트를 처리할 쓰레드를 실행시킵니다.
}
public void run() {
try {
while (true) {
// readLine()은 데이터가 들어올 때까지 기다리는
// 블로킹 메소드입니다.
String line = in.readLine();
if (line == null) { // 널 값은 스트림의 끝을 가리킵니다.
close();
break;
}
// 서버의 표준 출력으로 메시지 출력
System.out.println(getName()+':'+line);
// 모든 클라이언트에게 메시지 브로드캐스트
BroadcastServer.this.broadcast(line);
}
} catch (IOException ie) {
System.err.println(getName()+":IOException. "+ie.getMessage());
close();
}
}
public void close() {
synchronized (BroadcastServer.this) {
try { if (in!=null) in.close(); } catch (Exception e) { }
if (out!=null) out.close();
try { if (socket!=null) socket.close(); } catch (Exception e) { }
socket=null;
}
}
}
public BroadcastServer() {
// 먼저 지정된 포트로 서버 소켓을 생성합니다.
try {
server = new ServerSocket(PORT);
} catch (IOException ie) {
System.err.println("Cannot create server socket");
System.exit(1);
}
while (true) { // 무한 반복문 안에서 클라이언트의 접속을 기다립니다.
try {
Socket socket = server.accept();
// 클라이언트를 처리할 별도 쓰레드를 생성하고
// 클라이언트를 벡터 클래스에 추가합니다.
Client client = new Client(socket);
synchronized (this) {
clients.addElement(client);
}
} catch (IOException ie) {
System.err.println("IOException :"+ie.getMessage());
}
}
}
public static void main(String args[]) {
new BroadcastServer();
}
// 모든 클라이언트에게 메시지를 브로드캐스트하는 메소드
private synchronized void broadcast(String message) {
Vector v = new Vector(); // 지울 클라이언트를 잠시 저장
for (Enumeration enum=clients.elements();
enum.hasMoreElements(); )
{
Client client = (Client) enum.nextElement();
if (client == null)
continue;
if (client.socket == null) { // 소켓이 이미 닫긴 경우
v.addElement(client); // enumerate 중이므로 나중에 지우기 위해 저장
continue;
}
client.out.println(message);
if (client.out.checkError()) { // 에러 검사
System.err.println("Error while sending message.");
client.close();
}
}
// 여기에서 삭제할 목록을 실제로 삭제
for (Enumeration enum = v.elements();
enum.hasMoreElements(); )
{
Client client = (Client) enum.nextElement();
clients.removeElement(client);
}
}
}
<예제> 브로드캐스트 서버 프로그램
2.4.2 브로드캐스트 클라이언트 애플릿
브로드캐스트 애플릿은 일반적인 소켓 클라이언트 프로그램의 구조를 크게 벗어나지 않습니다. 다만 애플릿으로 구현할 것이기 때문에 고려해야 할 문제를 짚고 넘어가도록 합니다. 이전 호에서 애플릿을 다룰 때 언급했었지만 잘 기억나지 않는 독자들을 위해 상기시키자면 "애플릿 바이트코드가 있는 호스트 이외의 호스트와의 네트웍 접속"은 기본값으로 금지되어 있습니다.
쉽게 말하자면 애플릿이 위치하고 있는 웹 서버 이외의 호스트와는 네트웍으로 접속할 수 없습니다. 다시 말해서 애플릿과 접속할 소켓 서버는 애플릿이 위치한 웹 서버와 같은 호스트에서 실행되어야 합니다. 물론 애플릿을 일반 응용 프로그램처럼 보안 제약 없이 사용할 수 있는 애플릿 서명이란 기술을 사용하거나 자바 2에 추가된 퍼미션 지정 기능을 쓰면 다른 호스트와의 소켓 접속도 가능하지만, 번거로운 일일 것입니다. 여기에서는 애플릿이 존재하는 호스트에 소켓 접속하는 것으로 가정합니다.
애플릿 클래스의 getCodeBase() 메소드를 사용하여 다음과 같이 애플릿이 위치한 웹 서버의 호스트 이름을 구할 수 있습니다.
String hostname = getCodeBase().getHost();
다음은 브로드캐스트 서버에 접속할 클라이언트 애플릿 프로그램 코드입니다. 특기할 것은 별도의 쓰레드를 사용하여 서버가 보내는 메시지를 읽어들여 텍스트에리어에 디스플레이하는 일을 전담시키고 있다는 점입니다.
import java.awt.*;
import java.awt.event.*;
import java.applet.*;
import java.net.*;
import java.io.*;
public class BroadcastApplet extends Applet implements ActionListener
{
int port;
String host;
TextField inputField;
TextArea outputArea;
Socket socket;
BufferedReader in;
PrintWriter out;
Thread readingThread;
public void init() {
// 컴포넌트 레이아웃, 배치
inputField = new TextField();
outputArea = new TextArea();
setLayout(new BorderLayout());
add(inputField, "North");
add(outputArea, "Center");
String param=getParameter("PORT");
if (param==null)
port = 8001; // 기본 포트 번호
else
port = Integer.parseInt(param);
host=getParameter("HOST");
if (host==null) // 기본 호스트는 애플릿이 존재하는 호스트
host = getCodeBase().getHost();
inputField.addActionListener(this);
validate();
}
public void start() {
if (socket == null)
connect();
readingThread = new Thread() {
public void run() {
if (socket == null)
return;
while (socket!=null &&
readingThread==Thread.currentThread()) {
try {
// readLine() 메소드는 서버로부터
// 입력이 있을 때까지 블로킹된다.
String line = in.readLine();
appendLine(line);
} catch (IOException ie) {
appendLine("IOException:"+ie.getMessage());
closeSocket();
}
}
}
};
readingThread.start();
}
public void stop() {
readingThread=null;
closeSocket();
}
public void actionPerformed(ActionEvent ae) {
if (ae.getSource() instanceof TextField) {
String line = inputField.getText();
inputField.setText(""); // 텍스트에리어를 지웁니다.
if (socket == null)
return;
try {
out.println(line);
if (out.checkError())
throw new IOException("Print error.");
} catch (IOException ie) {
closeSocket();
}
}
}
public void connect() {
try {
socket = new Socket(host, port);
in = new BufferedReader(
new InputStreamReader(socket.getInputStream()));
out = new PrintWriter(
new OutputStreamWriter(socket.getOutputStream()),
true /* 자동 플러시 모드 */);
appendLine("Connected...");
} catch (UnknownHostException uhe) {
appendLine("Unknown host:"+uhe.getMessage());
} catch (IOException ie) {
appendLine("IOException:"+ie.getMessage());
}
}
public synchronized void closeSocket() {
try { if (in != null) in.close(); } catch (Exception e) { }
if (out != null) out.close();
try { if (socket != null) socket.close(); } catch (Exception e) { }
socket = null;
}
public synchronized void appendLine(String message) {
outputArea.append(message+"\n");
}
}
<예제> 브로드캐스트 클라이언트 애플릿 프로그램
클라이언트 애플릿 실행을 위한 HTML 문서는 다음과 같은 내용을 포함하면 됩니다.
<APPLET CODE=BroadcastApplet WIDTH=200 HEIGHT=200>
<PARAM NAME="PORT" VALUE=8001>
<PARAM NAME="HOST" VALUE="127.0.0.1">
</APPLET>
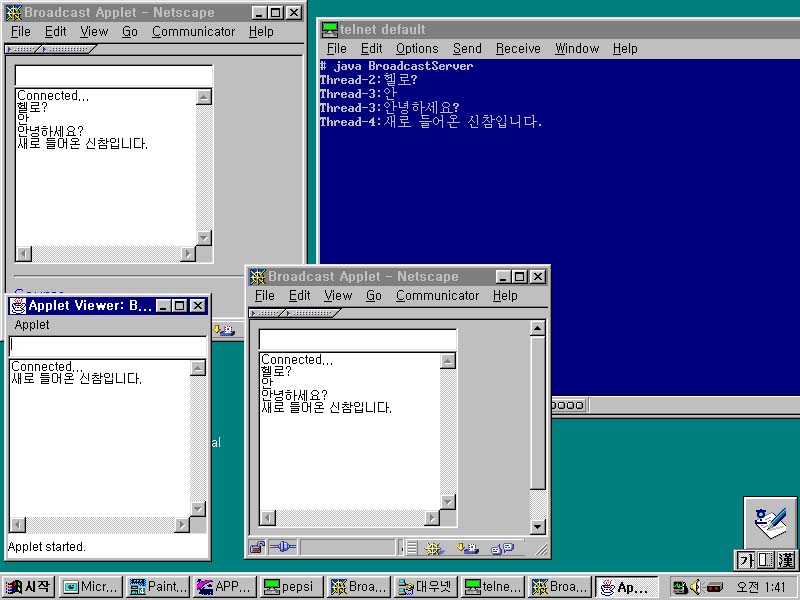
<그림> 브로드캐스트 서버/클라이언트 실행 모습
네트웍 프로그래밍은 약속을 중시하는 프로그래밍 분야입니다. 서버와 클라이언트 간의 대화에는 일정한 규약이 있어 이를 지키지 않을 경우, 에러 상황으로 빠지도록 설계되어야 합니다. 이러한 규약 혹은 약속을 흔히 프로토콜이라고 부릅니다. 서버/클라이언트 프로그래밍에서는 프로토콜을 분명하고 효율적으로, 또 다양한 상황을 고려하여 설계해야 훌륭한 결과를 얻을 수 있습니다.
브로드캐스트 서버/클라이언트는 조금의 규약을 추가하면 채팅 서버/클라이언트로 발전시킬 수 있습니다. 직접 도전해보기 바랍니다.
|
한국 로캘로 시간 표현하기 로캘(locale)은 프로그램이 실행되는 환경 중 지역과 언어에 관한 정보를 뜻합니다. 즉, 대한민국이라는 지역에 대한 정보와 한글이라는 언어에 대한 정보를 말합니다. 자바는 로캘 정보를 표현하는 java.util 패키지의 Locale 클래스를 제공합니다. 우리가 보통 사용하는 로캘은 대한민국이라는 지역의 측면에서 보면 Locale.KOREA이고 한글이라는 언어의 측면에서 보면 Locale.KOREAN입니다. Locale의 생성자를 사용하여 우리가 사용하는 로캘을 표현하려면 다음과 같이 할 수 있습니다.
로캘 생성자의 인자로 주어지는 언어값과 지역값은 국제 표준화 기구인 ISO에 의해 정해져 있습니다. 한글은 "ko", 대한민국은 "KR"로 지정되어 있습니다. 로캘이 달라지면 날짜와 시간, 도량형을 표현하는 방식이 달라집니다. 이렇게 로캘마다 다른 방식으로 날짜, 시간, 도량형 등을 표시하는 기능을 담당하는 자바 클래스들은 대부분 java.text 패키지에 들어 있습니다. 한 예로 날짜와 시간을 표현하는 DateFormat 클래스를 사용하여 입맛에 맞는 서식으로 시간을 표현해봅시다. java.text 패키지에 있는 Format으로 끝나는 이름의 클래스들은 보통 로캘에 의존하는 정보의 형식들을 서식화해주는 클래스들로 format() 메소드를 사용하여 서식화된 문자열을 만드는 데 사용됩니다. 다음은 현재의 기본 로캘을 사용하여 현재 시간을 기본 형식으로 출력하는 코드입니다.
필자의 윈도우 95에서 위 내용을 실행하면 다음과 같은 결과가 나옵니다.
좀더 친절하게 시간 정보를 나타내려고 한다면 DateFormat 객체 생성 부분을 다음과 같이 변경하면 됩니다.
이제 결과는 다음과 같이 나타납니다.
만약 사용하는 로캘 환경이 다르다면 동일한 코드가 다른 결과를 보여줄 것입니다. 로캘이 Locale.US로 지정되어 있다면 다음과 같은 결과가 나옵니다.
날짜/시간을 표현할 때 로캘과 더불어 대한민국에 사는 프로그래머가 관심을 가지는 문제는 타임존의 표현 문제입니다. 흔히 한국 표준시라는 타임존은 국제적으로 KST라는 이름으로 통용될 법하지만 JDK 1.2에서는 기껏 "Asia/Seoul"이라는 이름으로 어렵게 제공됩니다. "KST"라는 이름이나 "한국 표준시"라는 이름의 타임존 객체를 하나 생성하려면 다음과 같이 SimpleTimeZone 클래스를 사용하면 됩니다.
이 방법은 다사용자, 다중 로캘 지원 시스템인 유닉스 서버에서 실행되는 웹 서버쪽 프로그램인 서블릿 등에서 유용하게 사용할 수 있습니다. |
|
문자열의 인코딩 변환 자바 문자열의 인코딩을 변환시키는 것은 어렵지 않습니다. 바이트 배열을 지정된 문자 인코딩에 따라 String 객체로 변환하는 String 클래스 생성자를 사용하면 됩니다.
EUC_KR 인코딩에 따라 만들어둔 텍스트 파일에서 내용을 읽어 이것을 8859_1 인코딩으로도 표현해보고 EUC_KR 인코딩으로도 표현해보겠습니다. 영어를 포함한 기본 라틴 문자를 표현하는 8859_1 인코딩은 모든 문자를 1바이트로 처리하지만, EUC_KR 인코딩은 한글을 처리하기 위해 특정 영역의 문자코드는 2바이트 문자를 해석합니다. 따라서 파일로부터 읽어들인 바이트 배열 중 한글에 해당하는 부분을 8859_1 인코딩에서는 두 개의 1바이트 문자로 해석하고 EUC_KR 인코딩에서는 하나의 한글 문자로 해석할 것입니다. 먼저 예제로 쓸 텍스트 파일을 만듭니다. 여기에서는 아주 간단하게 10개의 문자로 구성된 텍스트 파일을 만들어 파일 이름을 test.txt라고 하겠습니다.
한글 윈도우 95/98/NT 등에서 이 파일을 저장하면 일반적으로 EUC_KR 인코딩에 따라 저장될 것입니다.
다음은 이 파일을 읽어들여 8859_1 인코딩과 EUC_KR 인코딩으로 각각 해석해 문자열을 출력하는 프로그램입니다.
실행해보면 다음과 같은 결과를 볼 수 있습니다.
바이트 배열을 8859_1 인코딩으로 해석하여 변환한 문자열은 한글을 두 개의 문자로 잘못 해석하였고, EUC_KR 인코딩으로 해석한 경우에만 제대로 보여줌을 확인할 수 있습니다. 이렇게 인코딩을 잘못 해석한 문자열을 다시 다른 인코딩으로 변환할 수도 있습니다. 다음은 8859_1로 인코딩된 위의 ascii 문자열 변수를 EUC_KR 인코딩으로 다시 변환하는 방법을 보여줍니다.
|
|
핵심 체크 ◈ 자바에서는 입출력을 위해 스트림을 일관되게 사용한다. ◈ 자바의 입출력 스트림에는 일반적인 데이터 입출력에 사용되는 바이트 입출력 스트림과 문자열 입출력을 위한 문자 입출력 스트림이 있다. ◈ 한글을 포함한 다국어 환경을 지원하는 문자열 입출력을 위해서는 문자 입출력 스트림을 사용해야 한다. ◈ 자바의 URL 클래스를 사용하면 쉽게 HTTP와 FTP 전송 프로토콜을 사용할 수 있다. ◈ ServerSocket과 Socket 클래스는 각각 클라이언트/서버 환경을 위한 서버와 클라이언트 소켓을 지원한다. |
필자 연락처 : yoonforh@yahoo.com